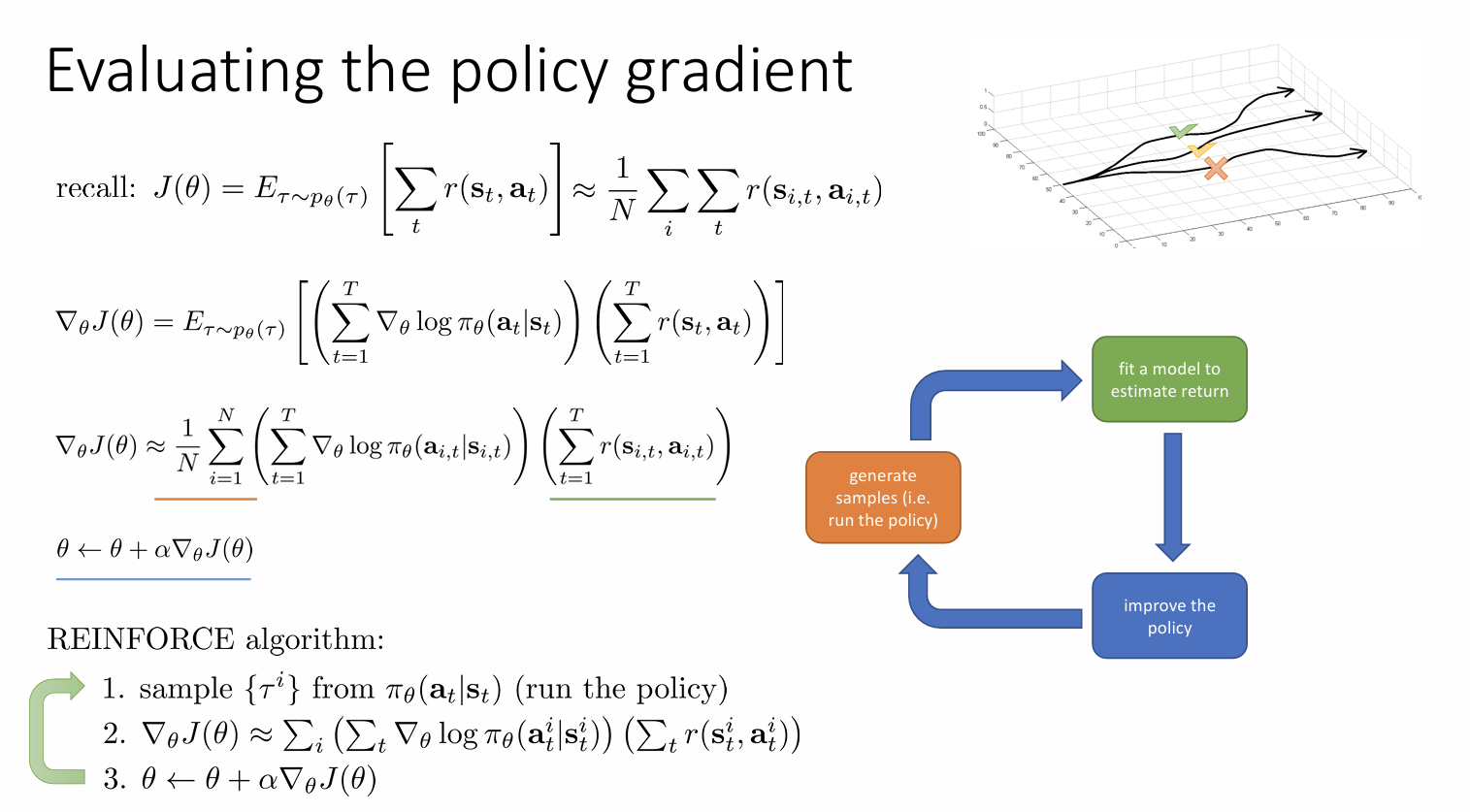
强化学习算法
policy gradients
algorithm
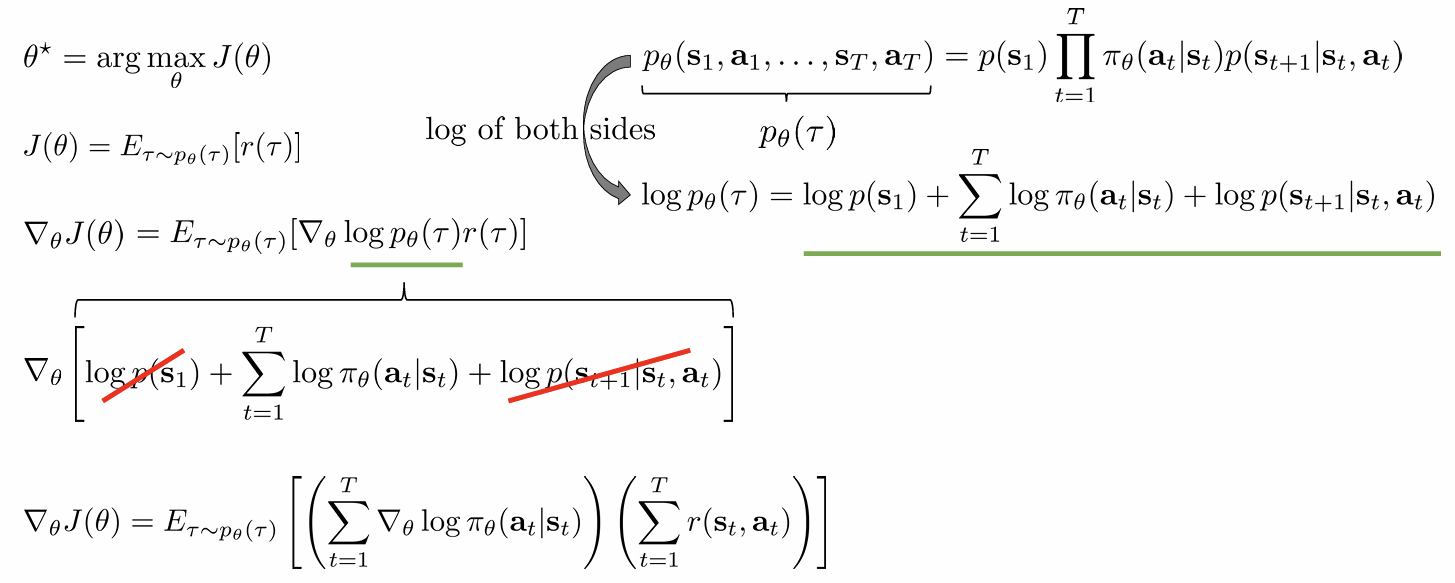
具体推导过程: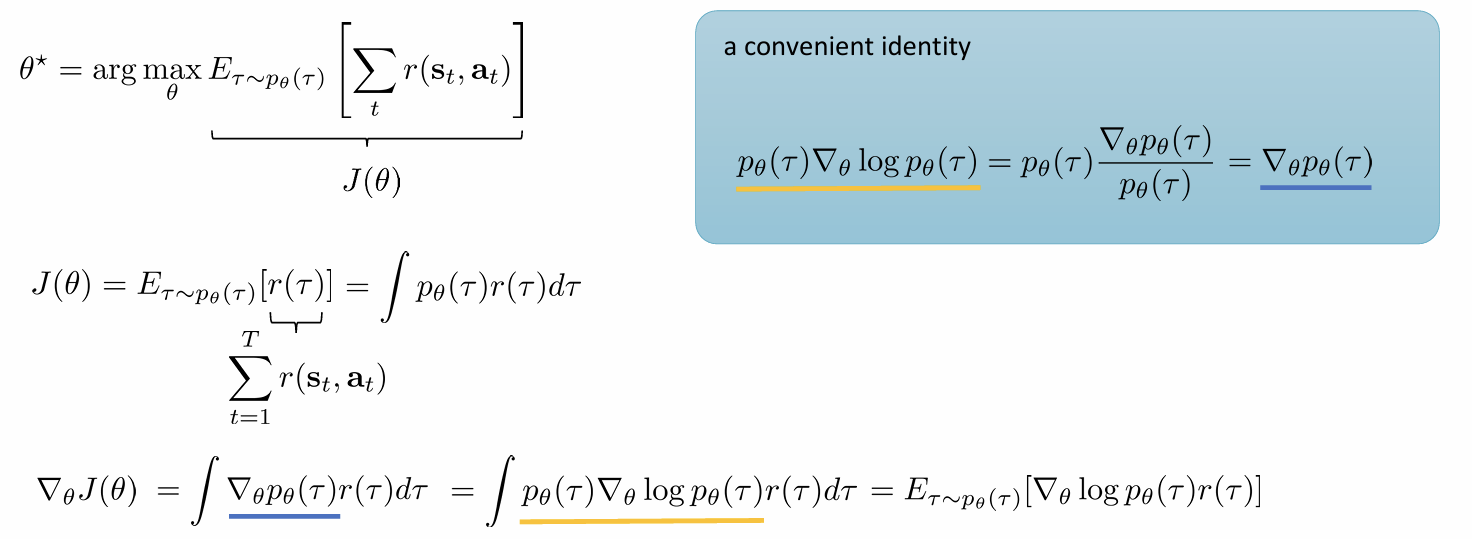
reduce the high-variance
强化学习出现高方差原因:策略更新所依赖的奖励信号,不仅包含了动作的真实价值,也包含了大量的随机噪声和不准确的因果关系。
baseline
Baseline提供了一个对当前状态下预期回报的平滑估计,通过从实际回报中减去这个预期值抵消大部分由于环境随机性导致的波动,并且在减少方差的同时,不改变策略梯度的期望值。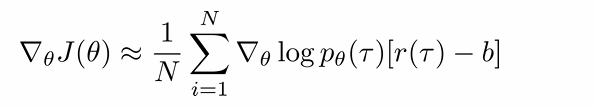
通常使用状态价值函数V(st)作为baseline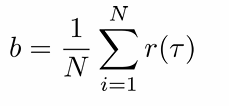
无偏估计 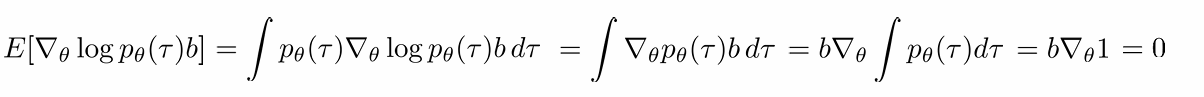
最优基线
梯度幅度大的轨迹,对策略梯度的估计影响大,通过使用梯度大小的平方作为权重,更有效地抵消这些高影响力轨迹带来的方差,从而使整体方差达到最小。
reward to go
从策略梯度公式中移除了与当前动作无关的过去奖励项,确保每个动作的价值评估只与其之后发生的奖励相关,建立更准确的因果关系。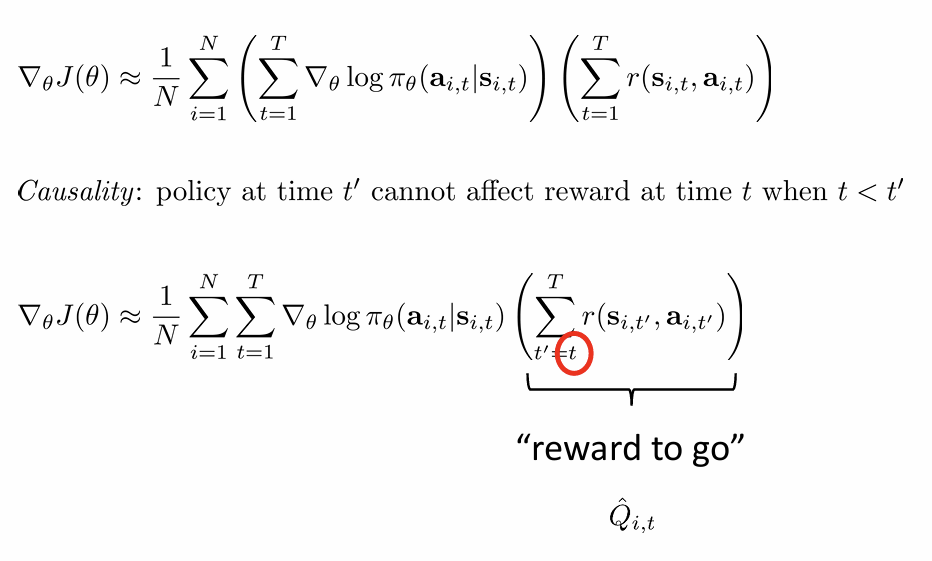
off-policy[^1] policy gradients
importance sampling重要性采样
使用行为策略生成的数据来评估或更新目标策略
因果重要性采样比率:为了评估动作 at,我们只需要考虑在它发生之前,两个策略之间的差异。因为在它发生之后,所有未来的动作还没有发生,它们与评估动作 at 的权重无关。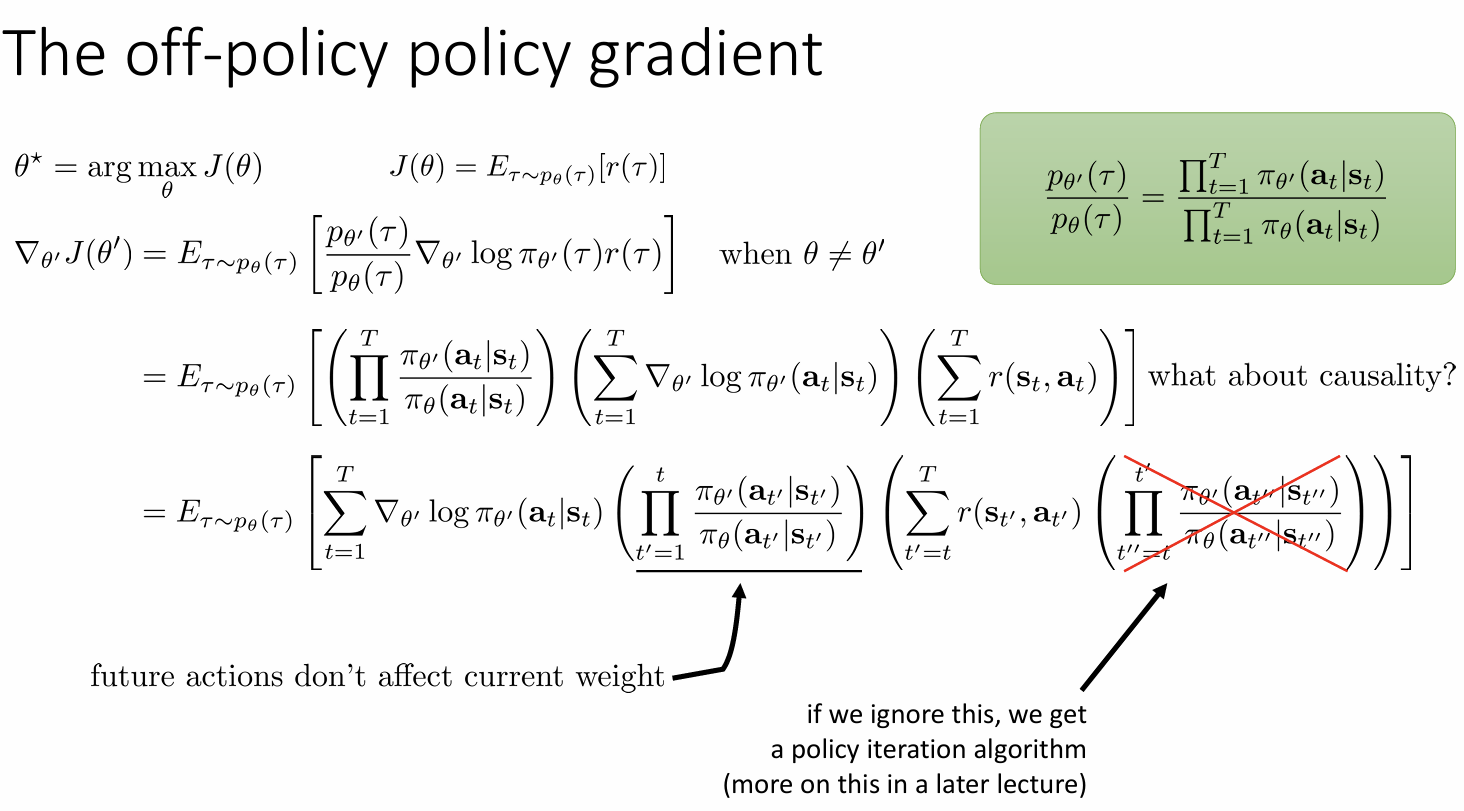
advanced policy gradients
策略某些参数可能比其他参数更能显著改变概率,而其他参数的变化则非常小 。而为了解决参数尺度不一致的问题,自然策略梯度会重新调整梯度,以确保参数空间中特定大小的策略更新,对应于策略行为中相似程度的变化 。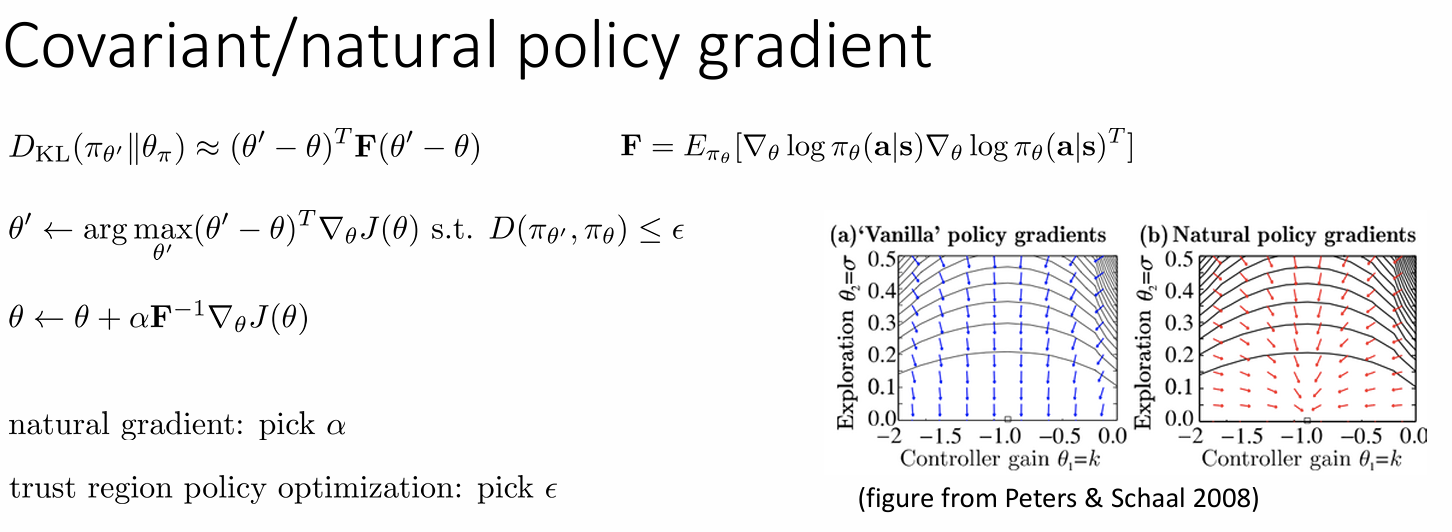
引入费雪信息矩阵二次型作为KL散度的近似进行约束,实现在策略分布变化不大的前提下,最大化策略性能。
[^1] :on-policy和off-policy,关注策略相关性。前者学习和决策都使用同一个策略,智能体根据当前正在优化的策略来选择动作,并使用这些动作和对应的回报来更新这个策略;后者学习和决策使用不同的策略,行为策略 (behavior policy) μ 负责生成数据,而另一个目标策略 (target policy) π 负责学习和更新,数据利用率更高。